
Debugging a Failing Application
This section assumes you’ve followed the steps in theGetting Started guide and have Linkerd and the demoapplication running in a Kubernetes cluster.
Using Linkerd to debug a failing application
The demo application has some issues. Let’s use Linkerd to diagnose theseissues.
If you glance at the Linkerd dashboard (by running the linkerd dashboardcommand), you should see all the resources in the emojivoto namespace,including the deployments. Each deployment running Linkerd shows success rate,requests per second and latency percentiles.
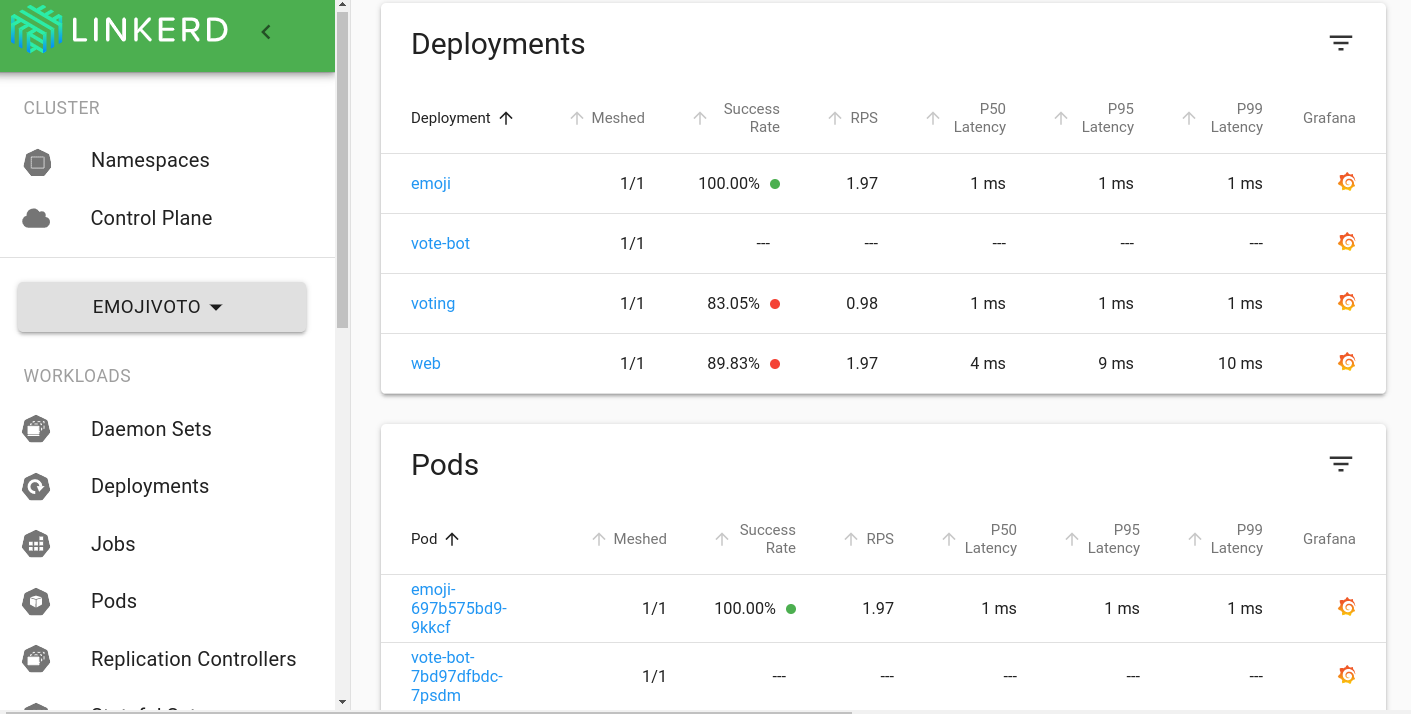
That’s pretty neat, but the first thing you might notice is that the successrate is well below 100%! Click on web and let’s dig in.
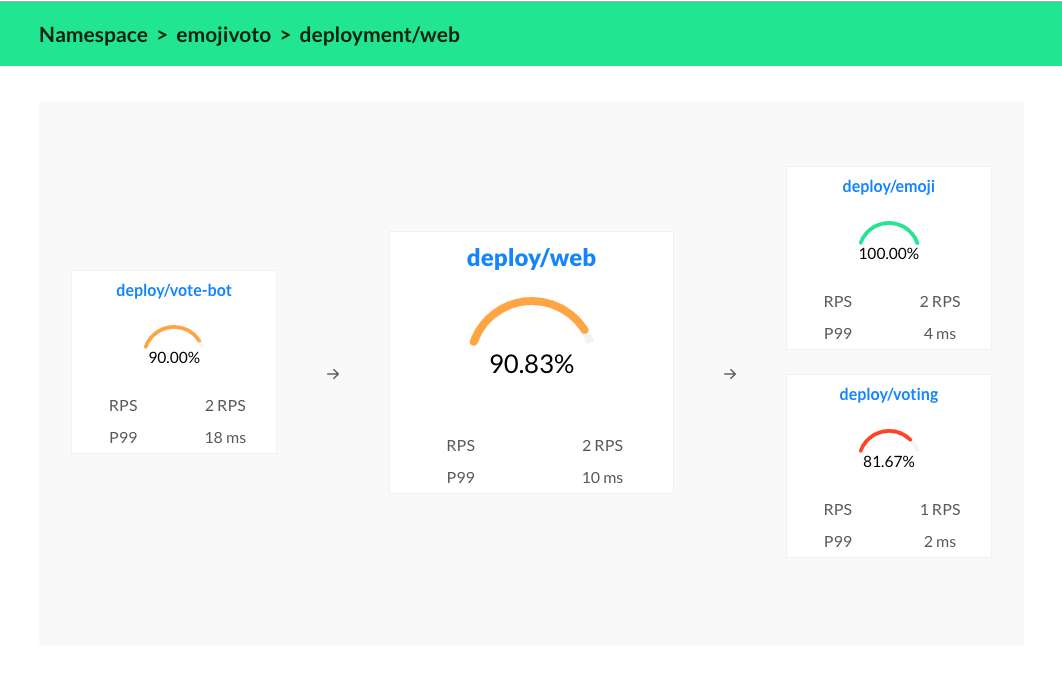
You should now be looking at the Deployment page for the web deployment. The firstthing you’ll see here is that the web deployment is taking traffic from vote-bot(a deployment included with emojivoto to continually generate a low level oflive traffic). The web deployment also has two outgoing dependencies, emojiand voting.
While the emoji deployment is handling every request from web successfully, itlooks like the voting deployment is failing some requests! A failure in a dependentdeployment may be exactly what is causing the errors that web is returning.
Let’s scroll a little further down the page, we’ll see a live list of alltraffic that is incoming to and outgoing from web. This is interesting:
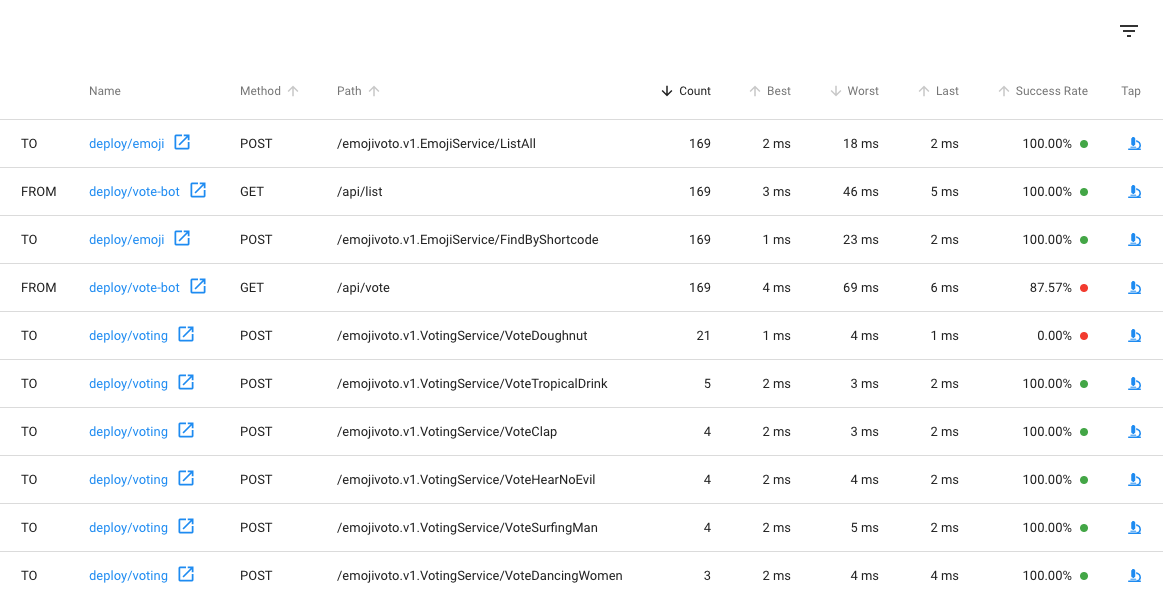
There are two calls that are not at 100%: the first is vote-bot’s call to the/api/vote endpoint. The second is the VotePoop call from the web deployment toits dependent deployment, voting. Very interesting! Since /api/vote is anincoming call, and VotePoop is an outgoing call, this is a good clue that thisendpoint is what’s causing the problem!
Finally, to dig a little deeper, we can click on the tap icon in the far rightcolumn. This will take us to the live list of requests that match only thisendpoint. We can confirm that the requests are failing (they all have agRPC status code 2,indicating an error).
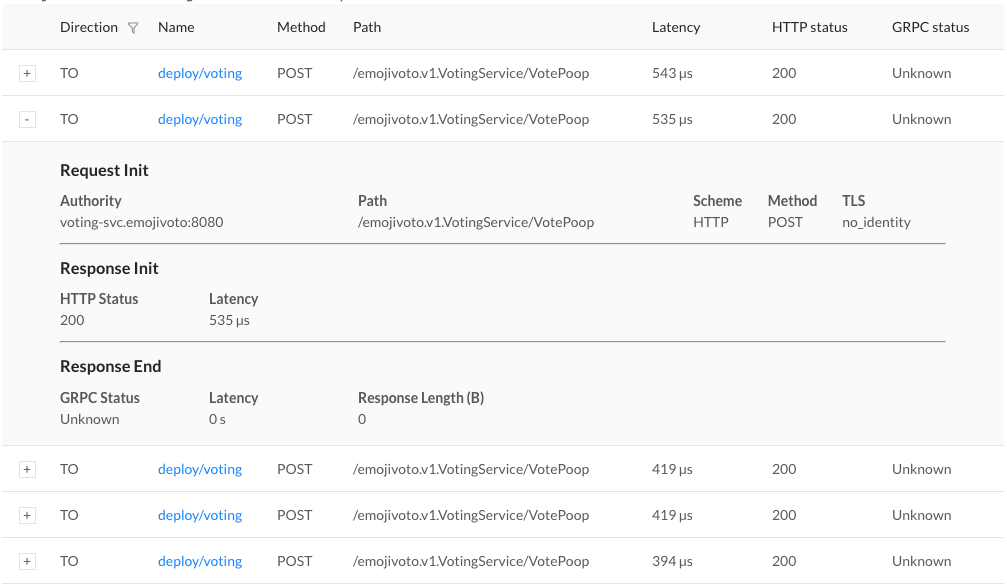
At this point, we have everything required to get the endpoint fixed and restorethe overall health of our applications.


