 服务器优惠
服务器优惠-

Apache Flink v1.12 Documentation
Apache Flink 是一个在无界和有界数据流上进行状态计算的框架和分布式处理引擎。 Flink 已经可以在所有常见的集群环境中运行,并以 in-memory 的速度和任意的规模进行计算。 -

Apache Flink v1.20 Documentation
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 -

Apache Flink v1.19 Documentation
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 -

编程笔记 By billryan
弹指之间,从我开始接触编程至今已五年有余,从大一刚接触 C 语言到现在对计算机编程的一知半解,其中曲折坎坷一言难尽,这本在线笔记记录了我在学习计算机编程过程中的点点滴滴。 -

Spark GraphX源码分析
Spark GraphX是一个新的Spark API,它用于图和分布式图(graph-parallel)的计算。GraphX 综合了 Pregel 和 GraphLab 两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算。 -

Apache Flink v1.11.1 Documentation
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 -

Apache Flink v1.14 Documentation
Apache Flink 是一个在无界和有界数据流上进行状态计算的框架和分布式处理引擎。 Flink 已经可以在所有常见的集群环境中运行,并以 in-memory 的速度和任意的规模进行计算。 -

Apache Flink v1.19 中文文档
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 -
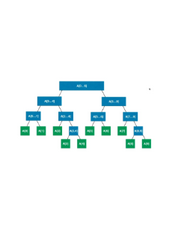
胡伟煌 数据结构 学习笔记
在计算机科学中,数据结构是计算机中存储、组织数据的方式。 数据结构意味着接口或封装:一个数据结构可被视为两个函数之间的接口,或者是由数据类型联合组成的存储内容的访问方法封装。 大多数数据结构都由数列、记录、可辨识联合、引用等基本类型构成。 -

InfluxDB简明手册
InfluxDB是一个开源的时序数据库,使用GO语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。而InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。