
概述
Vearch 是对大规模深度学习向量进行高性能相似搜索的弹性分布式系统。
基础概念
集群(cluster):vearch集群通常包括若干个节点,分为分布式集群和单机两种。
节点(node):vearch 包括三种节点,master节点(元数据管理节点)、router节点(路由计算节点)、partition server节点(数据存储计算节点)。
库(db):类似于数据库,首先集群中会先创建库。
表(space):类似于数据库的表,库包含若干个表。
分片(partition):通常每个表会包含若干个数据分片,每个数据分片只包含表的部分数据,对应partition_num。
副本(replica): 每个数据分片可以有多个副本,用来保障高可用和提高集群性能(如QPS等),对应replica_num。
文档(document):表的基础数据单元,每个文档通常包含若干个字段,一般而言文档至少包含一个向量字段。
字段(field):文档的基础数据单元,包括向量字段和标量字段(数值类型integer、long、float、double和字符串类型string)。
向量索引:利用向量索引来进行查询加速,因此向量字段都要设置index属性为true。
标量索引:对标量字段进行检索,如果要对某个字段进行查询,则必须设置对应的字段index属性为true。
整体架构
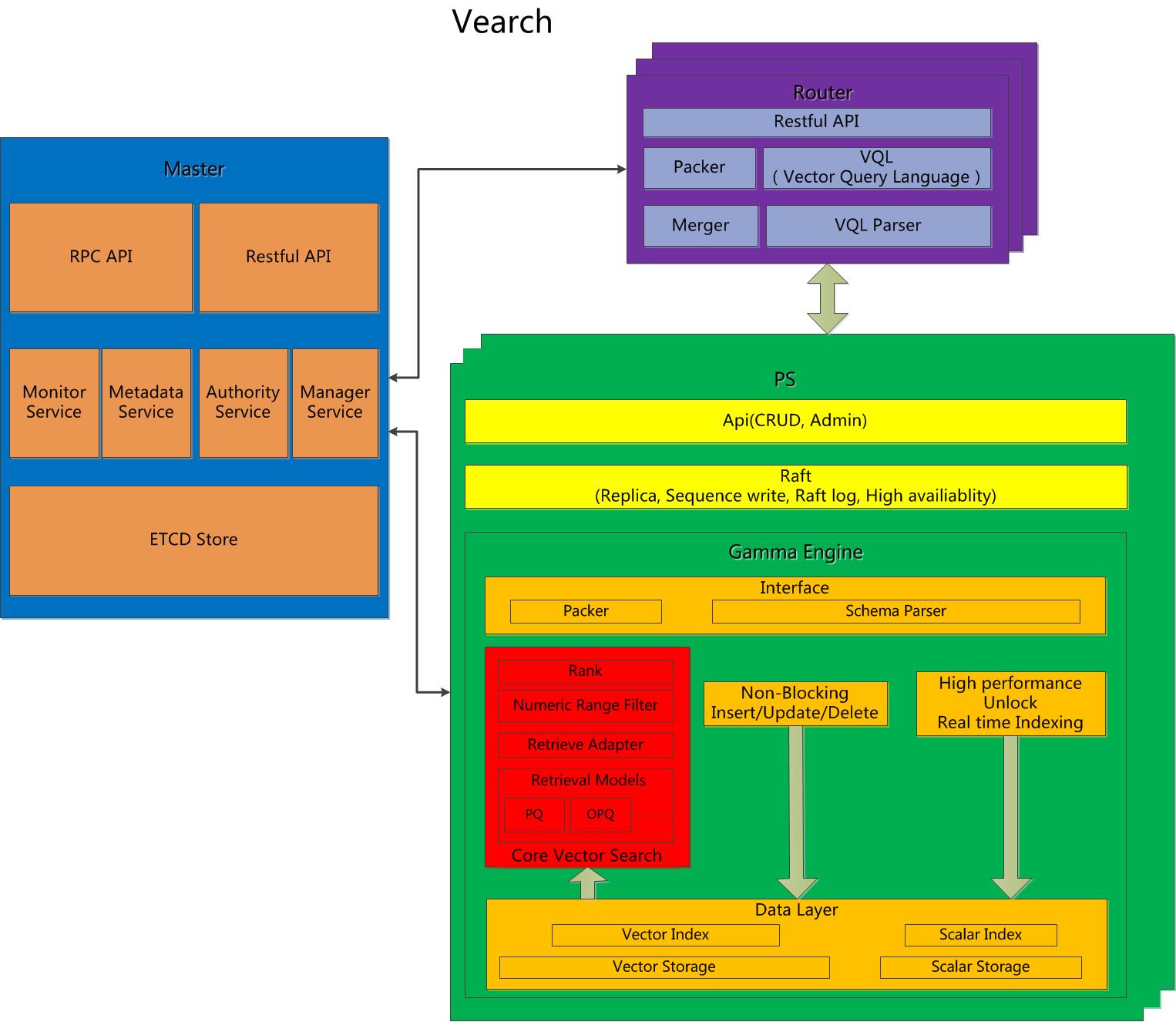
数据模型: 空间,文档,向量,标量。
组件: Master,Router,PartitionServer。
Master: 负责schema管理,集群级别的源数据和资源协调。
Router: 提供RESTful API: create、delete、search、update; 请求路由转发及结果合并。
PartitionServer(PS): 基于raft复制的文档分片; Gamma向量搜索引擎,它提供了存储、索引和检索向量、标量的能力。
功能简介
1、支持CPU与GPU两种版本。
2、支持实时添加数据到索引。
3、支持单个文档定义多个向量字段, 添加、搜索批量操作。
4、支持数值字段范围过滤与string字段标签过滤,支持向量和标量混合检索。
5、支持IVFPQ、HNSW、二进制等索引方式。
6、支持Python SDK本地快速开发验证。
7、支持机器学习算法插件方便系统部署使用。
系统特性
1、自研gamma引擎,提供高性能的向量检索。
2、IVFPQ倒排索引支持compaction,检索性能不受文档更新次数的影响。
3、支持内存、磁盘两种数据存储方式,支持超大数据规模。
4、基于raft协议实现数据多副本存储。
5、支持内积(InnerProduct)与欧式距离(L2)方法计算向量距离。


