
Analyze Slow Queries
To address the issue of slow queries, you need to take the following two steps:
- Among many queries, identify which type of queries are slow.
- Analyze why this type of queries are slow.
You can easily perform step 1 using the slow query log and the statement summary table features. It is recommended to use TiDB Dashboard, which integrates the two features and directly displays the slow queries in your browser.
This document focuses on how to perform step 2 - analyze why this type of queries are slow.
Generally, slow queries have the following major causes:
- Optimizer issues, such as wrong index selected, wrong join type or sequence selected.
- System issues. All issues not caused by the optimizer are system issues. For example, a busy TiKV instance processes requests slowly; outdated Region information causes slow queries.
In actual situations, optimizer issues might cause system issues. For example, for a certain type of queries, the optimizer uses a full table scan instead of the index. As a result, the SQL queries consume many resources, which causes the CPU usage of some TiKV instances to soar. This seems like a system issue, but in essence, it is an optimizer issue.
To identify system issues is relatively simple. To analyze optimizer issues, you need to determine whether the execution plan is reasonable or not. Therefore, it is recommended to analyze slow queries by following these procedures:
- Identify the performance bottleneck of the query, that is, the time-consuming part of the query process.
- Analyze the system issues: analyze the possible causes according to the query bottleneck and the monitoring/log information of that time.
- Analyze the optimizer issues: analyze whether there is a better execution plan.
The procedures above are explained in the following sections.
Identify the performance bottleneck of the query
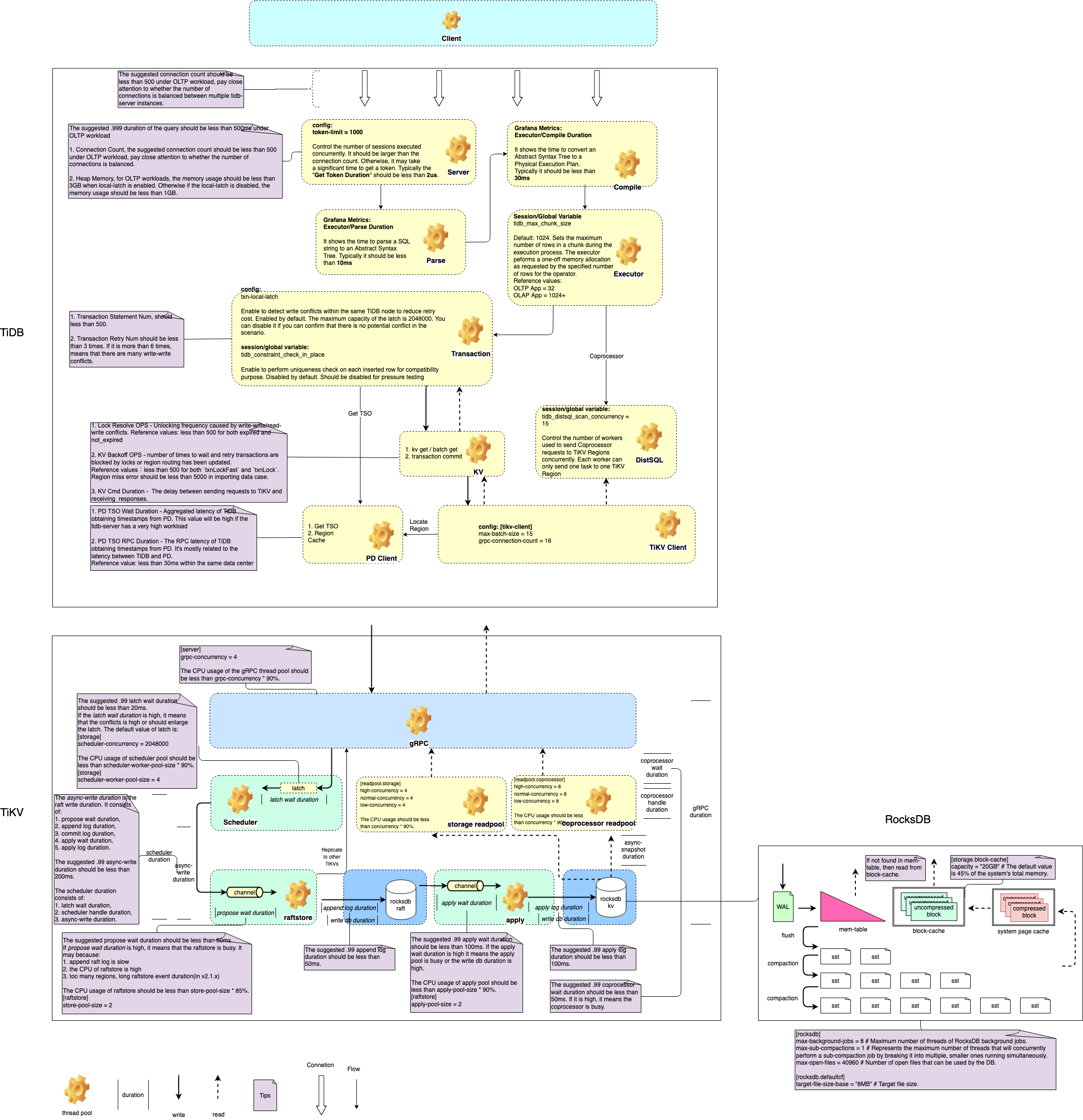
First, you need to have a general understanding of the query process. The key stages of the query execution process in TiDB are illustrated in TiDB performance map.
You can get the duration information using the following methods:
- Slow log. It is recommended to view the slow log in TiDB Dashboard.
- EXPLAIN ANALYZE statement.
The methods above are different in the following aspects:
- The slow log records the duration of almost all stages of a SQL execution, from parsing to returning results, and is relatively comprehensive (you can query and analyze the slow log in TiDB Dashboard in an intuitive way).
- By executing
EXPLAIN ANALYZE, you can learn the time consumption of each operator in an actual SQL execution. The results have more detailed statistics of the execution duration.
In summary, the slow log and EXPLAIN ANALYZE statements help you determine the SQL query is slow in which component (TiDB or TiKV) at which stage of the execution. Therefore, you can accurately identify the performance bottleneck of the query.
In addition, since v4.0.3, the Plan field in the slow log also includes the SQL execution information, which is the result of EXPLAIN ANALYZE. So you can find all information of SQL duration in the slow log.
Analyze system issues
System issues can be divided into the following types according to different execution stages of a SQL statement:
- TiKV is slow in data processing. For example, the TiKV coprocessor processes data slowly.
- TiDB is slow in execution. For example, a
Joinoperator processes data slowly. - Other key stages are slow. For example, getting the timestamp takes a long time.
For each slow query, first determine to which type the query belongs, and then analyze it in detail.
TiKV is slow in data processing
If TiKV is slow in data processing, you can easily identify it in the result of EXPLAIN ANALYZE. In the following example, StreamAgg_8 and TableFullScan_15, two tikv-tasks (as indicated by cop[tikv] in the task column), take 170ms to execute. After subtracting 170ms, the execution time of TiDB operators account for a very small proportion of the total execution time. This indicates that the bottleneck is in TiKV.
+----------------------------+---------+---------+-----------+---------------+------------------------------------------------------------------------------+---------------------------------+-----------+------+| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |+----------------------------+---------+---------+-----------+---------------+------------------------------------------------------------------------------+---------------------------------+-----------+------+| StreamAgg_16 | 1.00 | 1 | root | | time:170.08572ms, loops:2 | funcs:count(Column#5)->Column#3 | 372 Bytes | N/A || └─TableReader_17 | 1.00 | 1 | root | | time:170.080369ms, loops:2, rpc num: 1, rpc time:17.023347ms, proc keys:28672 | data:StreamAgg_8 | 202 Bytes | N/A || └─StreamAgg_8 | 1.00 | 1 | cop[tikv] | | time:170ms, loops:29 | funcs:count(1)->Column#5 | N/A | N/A || └─TableFullScan_15 | 7.00 | 28672 | cop[tikv] | table:t | time:170ms, loops:29 | keep order:false, stats:pseudo | N/A | N/A |+----------------------------+---------+---------+-----------+---------------+------------------------------------------------------------------------------+---------------------------------+-----------+------
In addition, the Cop_process and Cop_wait fields in the slow log can also help your analysis. In the following example, the total duration of the query is around 180.85ms, and the largest coptask takes 171ms. This indicates that the bottleneck of this query is on the TiKV side.
For the description of each field in the slow log, see fields description.
# Query_time: 0.18085...# Num_cop_tasks: 1# Cop_process: Avg_time: 170ms P90_time: 170ms Max_time: 170ms Max_addr: 10.6.131.78# Cop_wait: Avg_time: 1ms P90_time: 1ms Max_time: 1ms Max_Addr: 10.6.131.78
After identifying that TiKV is the bottleneck, you can find out the cause as described in the following sections.
TiKV instance is busy
During the execution of a SQL statement, TiDB might fetch data from multiple TiKV instances. If one TiKV instance responds slowly, the overall SQL execution speed is slowed down.
The Cop_wait field in the slow log can help you determine this cause.
# Cop_wait: Avg_time: 1ms P90_time: 2ms Max_time: 110ms Max_Addr: 10.6.131.78
The log above shows that a cop-task sent to the 10.6.131.78 instance waits 110ms before being executed. It indicates that this instance is busy. You can check the CPU monitoring of that time to confirm the cause.
Too many outdated keys
A TiKV instance has much outdated data, which needs to be cleaned up for data scan. This impacts the processing speed.
Check Total_keys and Processed_keys. If they are greatly different, the TiKV instance has too many keys of the older versions.
...# Total_keys: 2215187529 Processed_keys: 1108056368...
Other key stages are slow
Slow in getting timestamps
You can compare Wait_TS and Query_time in the slow log. The timestamps are prefetched, so generally Wait_TS should be low.
# Query_time: 0.0300000...# Wait_TS: 0.02500000
Outdated Region information
Region information on the TiDB side might be outdated. In this situation, TiKV might return the regionMiss error. Then TiDB gets the Region information from PD again, which is reflected in the Cop_backoff information. Both the failed times and the total duration are recorded.
# Cop_backoff_regionMiss_total_times: 200 Cop_backoff_regionMiss_total_time: 0.2 Cop_backoff_regionMiss_max_time: 0.2 Cop_backoff_regionMiss_max_addr: 127.0.0.1 Cop_backoff_regionMiss_avg_time: 0.2 Cop_backoff_regionMiss_p90_time: 0.2# Cop_backoff_rpcPD_total_times: 200 Cop_backoff_rpcPD_total_time: 0.2 Cop_backoff_rpcPD_max_time: 0.2 Cop_backoff_rpcPD_max_addr: 127.0.0.1 Cop_backoff_rpcPD_avg_time: 0.2 Cop_backoff_rpcPD_p90_time: 0.2
Subqueries are executed in advance
For statements with non-correlated subqueries, the subquery part might be executed in advance. For example, in select * from t1 where a = (select max(a) from t2), the select max(a) from t2 part might be executed in advance in the optimization stage. The result of EXPLAIN ANALYZE does not show the duration of this type of subqueries.
mysql> explain analyze select count(*) from t where a=(select max(t1.a) from t t1, t t2 where t1.a=t2.a);+------------------------------+----------+---------+-----------+---------------+--------------------------+----------------------------------+-----------+------+| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |+------------------------------+----------+---------+-----------+---------------+--------------------------+----------------------------------+-----------+------+| StreamAgg_59 | 1.00 | 1 | root | | time:4.69267ms, loops:2 | funcs:count(Column#10)->Column#8 | 372 Bytes | N/A || └─TableReader_60 | 1.00 | 1 | root | | time:4.690428ms, loops:2 | data:StreamAgg_48 | 141 Bytes | N/A || └─StreamAgg_48 | 1.00 | | cop[tikv] | | time:0ns, loops:0 | funcs:count(1)->Column#10 | N/A | N/A || └─Selection_58 | 16384.00 | | cop[tikv] | | time:0ns, loops:0 | eq(test.t.a, 1) | N/A | N/A || └─TableFullScan_57 | 16384.00 | -1 | cop[tikv] | table:t | time:0s, loops:0 | keep order:false | N/A | N/A |+------------------------------+----------+---------+-----------+---------------+--------------------------+----------------------------------+-----------+------+5 rows in set (7.77 sec)
But you can identify this type of subquery execution in the slow log:
# Query_time: 7.770634843...# Rewrite_time: 7.765673663 Preproc_subqueries: 1 Preproc_subqueries_time: 7.765231874
From log record above, you can see that a subquery is executed in advance and takes 7.76s.
TiDB is slow in execution
Assume that the execution plan in TiDB is correct but the execution is slow. To solve this type of issue, you can adjust parameters or use the hint according to the result of EXPLAIN ANALYZE for the SQL statement.
If the execution plan is incorrect, see the Analyze optimizer issues section.
Low concurrency
If the bottleneck is in the operator with concurrency, speed up the execution by adjusting the concurrency. For example:
mysql> explain analyze select sum(t1.a) from t t1, t t2 where t1.a=t2.a;+----------------------------------+--------------+-----------+-----------+---------------+-------------------------------------------------------------------------------------+------------------------------------------------+------------------+---------+| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |+----------------------------------+--------------+-----------+-----------+---------------+-------------------------------------------------------------------------------------+------------------------------------------------+------------------+---------+| HashAgg_11 | 1.00 | 1 | root | | time:9.666832189s, loops:2, PartialConcurrency:4, FinalConcurrency:4 | funcs:sum(Column#6)->Column#5 | 322.125 KB | N/A || └─Projection_24 | 268435456.00 | 268435456 | root | | time:9.098644711s, loops:262145, Concurrency:4 | cast(test.t.a, decimal(65,0) BINARY)->Column#6 | 199 KB | N/A || └─HashJoin_14 | 268435456.00 | 268435456 | root | | time:6.616773501s, loops:262145, Concurrency:5, probe collision:0, build:881.404µs | inner join, equal:[eq(test.t.a, test.t.a)] | 131.75 KB | 0 Bytes || ├─TableReader_21(Build) | 16384.00 | 16384 | root | | time:6.553717ms, loops:17 | data:Selection_20 | 33.6318359375 KB | N/A || │ └─Selection_20 | 16384.00 | | cop[tikv] | | time:0ns, loops:0 | not(isnull(test.t.a)) | N/A | N/A || │ └─TableFullScan_19 | 16384.00 | -1 | cop[tikv] | table:t2 | time:0s, loops:0 | keep order:false | N/A | N/A || └─TableReader_18(Probe) | 16384.00 | 16384 | root | | time:6.880923ms, loops:17 | data:Selection_17 | 33.6318359375 KB | N/A || └─Selection_17 | 16384.00 | | cop[tikv] | | time:0ns, loops:0 | not(isnull(test.t.a)) | N/A | N/A || └─TableFullScan_16 | 16384.00 | -1 | cop[tikv] | table:t1 | time:0s, loops:0 | keep order:false | N/A | N/A |+----------------------------------+--------------+-----------+-----------+---------------+-------------------------------------------------------------------------------------+------------------------------------------------+------------------+---------+9 rows in set (9.67 sec)
As shown above, HashJoin_14 and Projection_24 consume much of the execution time. Consider increasing their concurrency using SQL variables to speed up execution.
All system variables are documented in system-variables. To increase the concurrency of HashJoin_14, you can modify the tidb_hash_join_concurrency system variable.
Data is spilled to disk
Another cause of slow execution is disk spill that occurs during execution if the memory limit is reached. You can find out this cause in the execution plan and the slow log:
+-------------------------+-----------+---------+-----------+---------------+------------------------------+----------------------+-----------------------+----------------+| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |+-------------------------+-----------+---------+-----------+---------------+------------------------------+----------------------+-----------------------+----------------+| Sort_4 | 462144.00 | 462144 | root | | time:2.02848898s, loops:453 | test.t.a | 149.68795776367188 MB | 219.3203125 MB || └─TableReader_8 | 462144.00 | 462144 | root | | time:616.211272ms, loops:453 | data:TableFullScan_7 | 197.49601364135742 MB | N/A || └─TableFullScan_7 | 462144.00 | -1 | cop[tikv] | table:t | time:0s, loops:0 | keep order:false | N/A | N/A |+-------------------------+-----------+---------+-----------+---------------+------------------------------+----------------------+-----------------------+----------------+
...# Disk_max: 229974016...
Join operations with Cartesian product
Join operations with Cartesian product generate data volume as large as left child row count * right child row count. This is inefficient and should be avoided.
This type of join operations is marked CARTESIAN in the execution plan. For example:
mysql> explain select * from t t1, t t2 where t1.a>t2.a;+------------------------------+-------------+-----------+---------------+---------------------------------------------------------+| id | estRows | task | access object | operator info |+------------------------------+-------------+-----------+---------------+---------------------------------------------------------+| HashJoin_8 | 99800100.00 | root | | CARTESIAN inner join, other cond:gt(test.t.a, test.t.a) || ├─TableReader_15(Build) | 9990.00 | root | | data:Selection_14 || │ └─Selection_14 | 9990.00 | cop[tikv] | | not(isnull(test.t.a)) || │ └─TableFullScan_13 | 10000.00 | cop[tikv] | table:t2 | keep order:false, stats:pseudo || └─TableReader_12(Probe) | 9990.00 | root | | data:Selection_11 || └─Selection_11 | 9990.00 | cop[tikv] | | not(isnull(test.t.a)) || └─TableFullScan_10 | 10000.00 | cop[tikv] | table:t1 | keep order:false, stats:pseudo |+------------------------------+-------------+-----------+---------------+---------------------------------------------------------+
Analyze optimizer issues
To analyze optimizer issues, you need to determine whether the execution plan is reasonable or not. You need to have some understanding of the optimization process and each operator.
For the following examples, assume that the table schema is create table t (id int, a int, b int, c int, primary key(id), key(a), key(b, c)).
select * from t: There is no filter condition and a full table scan is performed. So theTableFullScanoperator is used to read data.select a from t where a=2: There is a filter condition and only the index columns are read, so theIndexReaderoperator is used to read data.select * from t where a=2: There is a filter condition forabut theaindex cannot fully cover the data to be read, so theIndexLookupoperator is used.select b from t where c=3: Without the prefix condition, the multi-column index cannot be used. So theIndexFullScanis used.- …
The examples above are operators used for data reads. For more operators, see Understand TiDB Execution Plan.
In addition, reading SQL Tuning Overview helps you better understand the TiDB optimizer and determine whether the execution plan is reasonable or not.
Most optimizer issues are explained in SQL Tuning Overview. For the solutions, see the following documents:



{kind=link}