
Longorn implements distributed block storage using containers and microservices. It creates a dedicated storage controller for each block device volume and synchronously replicates the volume across multiple replicas stored on multiple nodes. The storage controller and replicas are themselves orchestrated using Kubernetes.
The Longhorn manager is repsonsible for creating and managing volumes in the Kubernetes cluster.
When the Longhorn manager is asked to create a volume, it creates a controller container on the host the volume is attached to as well as the hosts where the replicas will be placed. Replicas should be placed on separate hosts to ensure maximum availability.
In the figure below, there are three containers with Longhorn volumes. Each Docker volume has a dedicated controller, which runs as a container. Each controller has two replicas and each replica is a container. The arrows in the figure indicate the read/write data flow between the Docker volume, controller container, replica containers, and disks. By creating a separate controller for each volume, if one controller fails, the function of other volumes is not impacted.
read/write data flow between the Docker volume, controller container, replica containers, and disks
For example, in a large-scale deployment with 100,000 Docker volumes each with two replicas, there will be 100,000 controller containers and 200,000 replica containers. In order to schedule, monitor, coordinate, and repair all these controllers and replicas a storage orchestration system is needed.
Replica Operations
Replica Operations
Longhorn replicas are built using Linux sparse files, which support thin provisioning. We currently do not maintain additional metadata to indicate which blocks are used. The block size is 4K. When you take a snapshot, you create a differencing disk. As the number of snapshots grows, the differencing disk chain could get quite long. To improve read performance, Longhorn therefore maintains a read index that records which differencing disk holds valid data for each 4K block.
In the following figure, the volume has eight blocks. The read index has eight entries and is filled up lazily as read operation takes place. A write operation resets the read index, causing it to point to the live data.
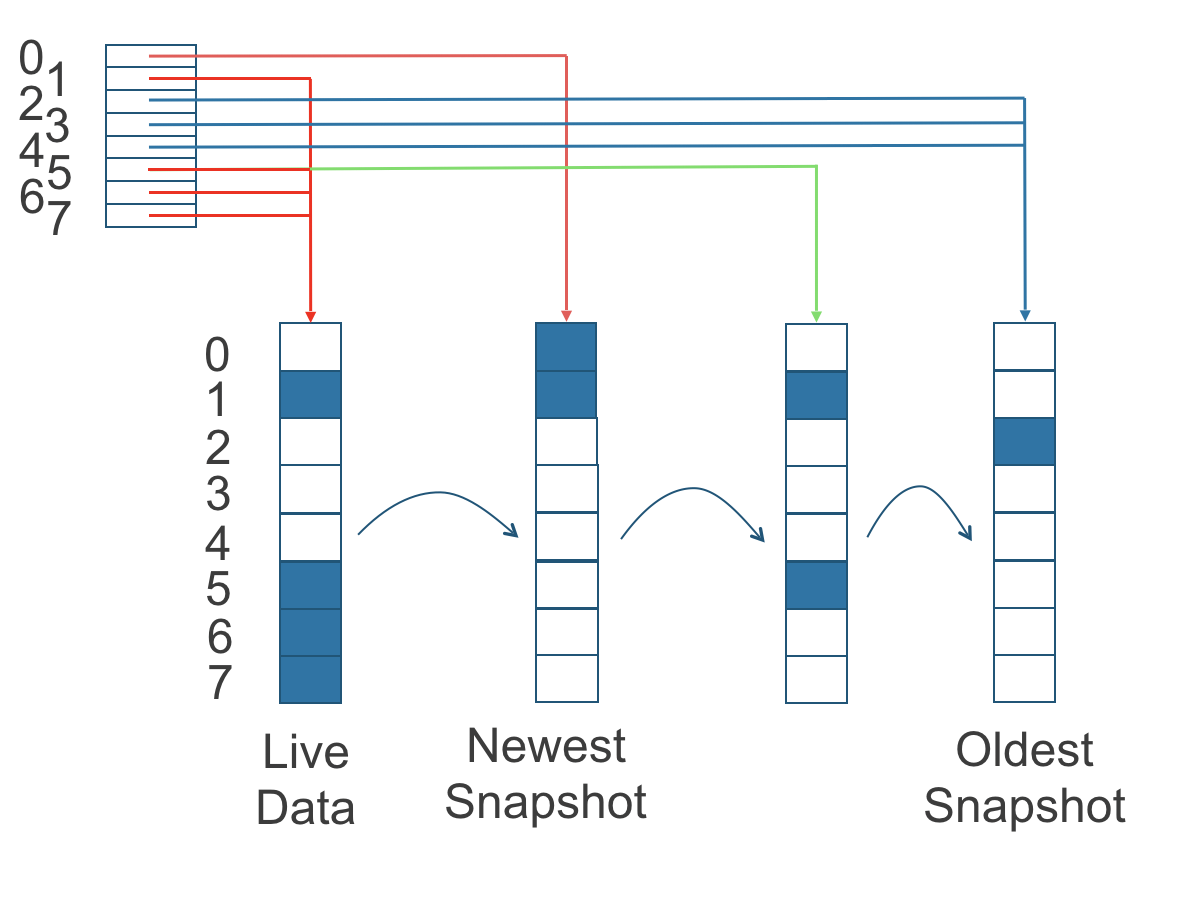
The read index is kept in memory and consumes one byte for each 4K block. The byte-sized read index means you can take as many as 254 snapshots for each volume. The read index consumes a certain amount of in-memory data structure for each replica. A 1TB volume, for example, consumes 256MB of in-memory read index. We will potentially consider placing the read index in memory-mapped files in the future.
Replica Rebuild
When the controller detects failures in one of its replicas, it marks the replica as being in an error state. The Longhorn volume manager is responsible for initiating and coordinating the process of rebuilding the faulty replica as follows:
- The Longhorn volume manager creates a blank replica and calls the controller to add the blank replica into its replica set.
- To add the blank replica, the controller performs the following operations:
- Pauses all read and write operations.
- Adds the blank replica in WO (write-only) mode.
- Takes a snapshot of all existing replicas, which will now have a blank differencing disk at its head.
- Unpauses all read the write operations. Only write operations will be dispatched to the newly added replica.
- Starts a background process to sync all but the most recent differencing disk from a good replica to the blank replica.
- After the sync completes, all replicas now have consistent data, and the volume manager sets the new replica to RW (read-write) mode.
- The Longhorn volume manager calls the controller to remove the faulty replica from its replica set.
Backup and Restore
Snapshot and backup operations are performed separately. The backups are incremental, detecting and transmitting the changed blocks between snapshots. This is a relatively easy task since each snapshot is a differencing file and only stores the changes from the last snapshot. To avoid storing a very large number of small blocks, Longhorn performs backup operations using 2MB blocks. That means that, if any 4K block in a 2MB boundary is changed, it will have to backup the entire 2MB block. This offers the right balance between manageability and efficiency.
In the following figure, Longhorn has backed up both “snap2” and “snap3”. Each backup maintains its own set of 2MB blocks, and the two backups share one green block and one blue block. Each 2MB block is backed up only once. When the user deletes a backup from secondary storage, Lonhgorn does not delete all the blocks it uses. Instead, it performs garbage collection periodically to clean up unused blocks from secondary storage.

Longhorn stores all backups for a given volume under a common directory. The following figure depicts a somewhat simplified view of how Longhorn stores backups for a volume. Volume-level metadata is stored in volume.cfg.
The metadata files for each backup (e.g., “snap2.cfg”) are relatively small because they only contain the offsets and check sums of all the 2MB blocks in the backup. The 2MB blocks for all backups belonging to the same volume are stored under a common directory and can therefore be shared across multiple backups. The 2MB blocks (.blk files) are compressed. Because checksums are used to address the 2MB blocks, we achieve some degree of deduplication for the 2MB blocks in the same volume.
Volume-level metadata is stored in volume.cfg. The metadata files for each backup (e.g., “snap2.cfg”) are relatively small because they only contain the offsets and check sums of all the 2MB blocks in the backup. The 2MB blocks for all backups belonging to the same volume are stored under a common directory and can therefore be shared across multiple backups. The 2MB blocks (.blk files) are compressed. Because check sums are used to address the 2MB blocks, we achieve some degree of deduplication for the 2MB blocks in the same volume.


