
Flume-Core
本章讲述Flume项目的核心表示层: 逻辑执行计划. 逻辑执行计划的执行请参见 算子执行框架
核心概念
Flume将分布式计算过程抽象为数据流在算子上的变换, 这就引申出了两个Flume中的核心概念: 算子和算子应用的范围. 接下来我们分别讲解这些概念.
Processor
在Flume中, 最核心的算子是Processor, 它接受N路数据流, 产出1路数据流. 我们这里举两个例子.
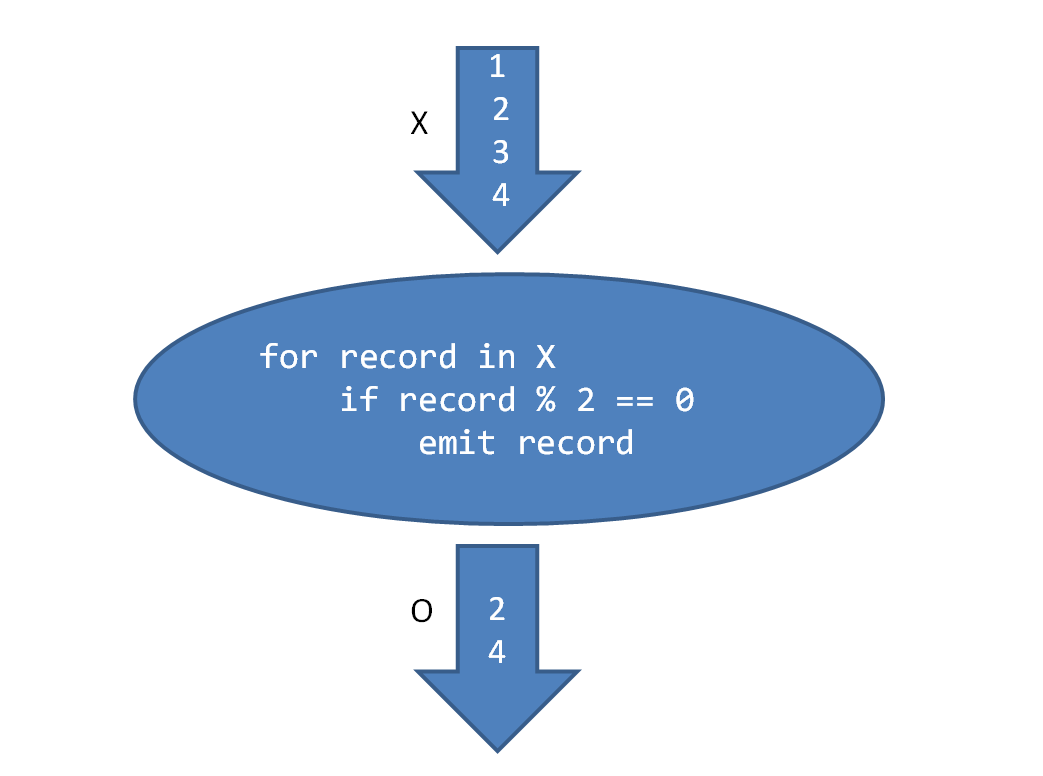
上图描述了FilterProcessor的逻辑, 它过滤掉的输入流X中的奇数数据, 得到一个新的数据流O.
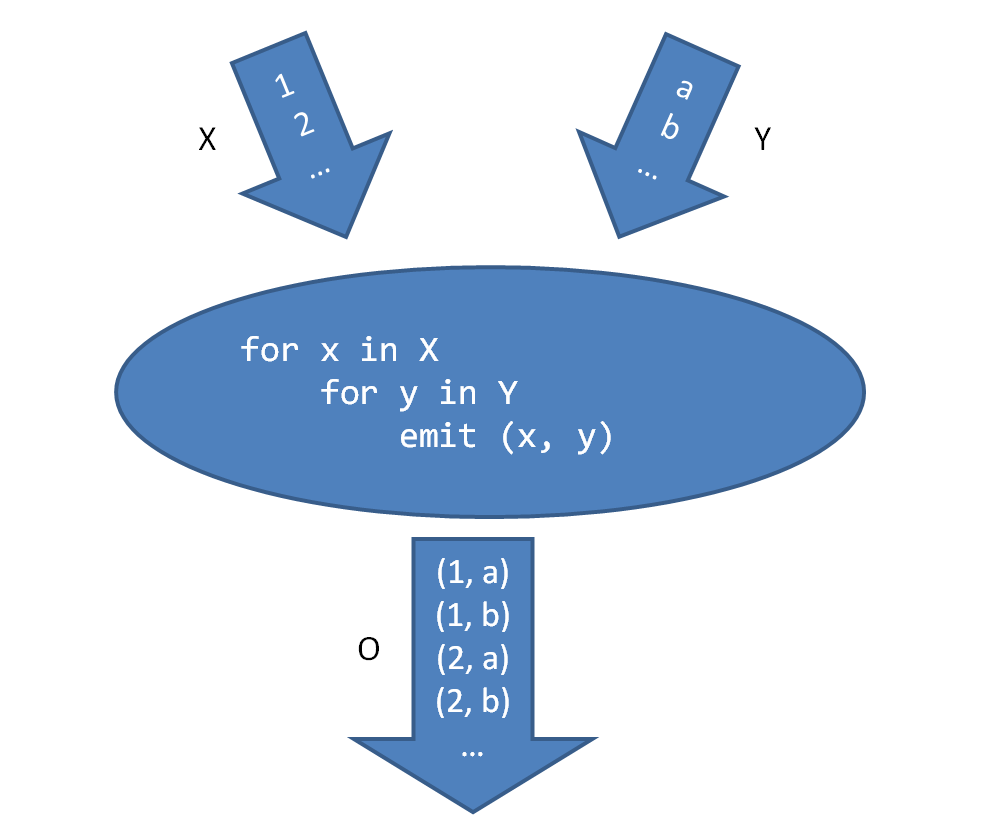
上图描述了CartesianProcessor的逻辑, 它有两路输入X Y, 输出是X和Y中数据的笛卡尔积.
Processor可以被串联/级联组成Dag, 如下图所示:
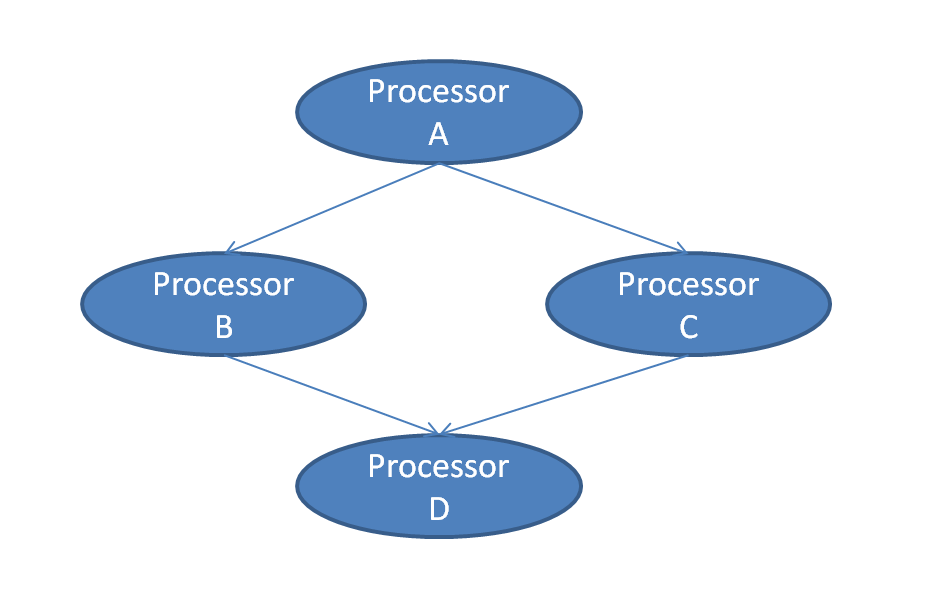
通过上图我们可以看到, Processor之间可以任意串联, 一个Processor后面也可以跟随任意个后继Processor, 然后后继的每个Processor在该路上得到的输入都是一样的, 比如B和C得到的输入就完全一样.
Group/Scope
Processor算子是Flume中的基本计算单元, 它体现了分布式计算中的’计算’, 我们需要另外的概念来描述’分布式’. 考虑下面的例子
select week, weekday, sum(sales_value)from sales_loggroup by rollup(week, weekday)orderby week, weekday
rollup是Oracle SQL数据库的概念, 含义是层级聚集, 具体到上面的例子, 就是分别以week和(week,weekday)作为分组应用进行求和, 其结果形如:
周 天 销售额 1 1 4363.55 1 2 4794.76 1 3 4718.25 1 4 5387.45 1 5 5027.34 1 24291.35 2 1 5652.84 2 2 4583.02 2 3 5555.77 2 4 5936.67 2 5 4508.74 2 26237.04 A 50528.39
我们看到, 所有这些输出都是SumProcessor的计算结果, 区别在于该算子应用的范围. 因此在Flume的定义中, 每个算子以Group为基本处理单位, 每次处理一组数据. 又因为分组是嵌套的, 如在{第一周销售记录}这一组数据, 又可按照工作日继续细分, 我们用Scope来面表达相同地位分组的集合. 每一个算子, 都必须置于某一个Scope下, 处理该Scope下所有Group的数据. 按照这种思路, 我们用如下图所示的逻辑执行计划来描述上述SQL的计算逻辑:
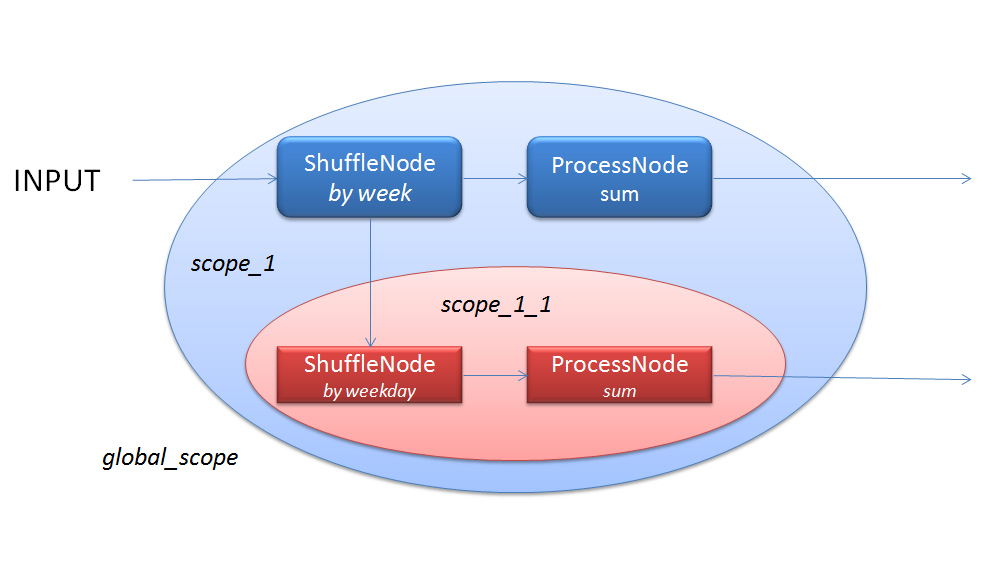
在Flume中, 我们用Shuffle这个名词来表达分组和排序. 一个Shuffle过程可以有N路输入源参与, 其结果表示为一个嵌套的Scope和其中的N个ShuffleNode, 每个ShuffleNode有一路输入和一路输出, 输入是参与Shuffle过程的输入源, 其输出可以被同Scope的后续算子操作.
逻辑执行计划
在上一节中, 我们讲述了Flume计算抽象的基本原则. 本节我们要讲述完整的核心表示层:逻辑执行计划. 首先我们介绍逻辑执行计划的各个组成部分.
Node
- 组成逻辑计划的基本单位
- Node上绑定着相应的自定义算子
- 每个Node上只有一路逻辑上的输出
- 逻辑执行计划上的所有Node组成一个DAG
Scope/Group
- Scope是地位相同的各个数据分组的集合
- Scope中的数据按key分组, 每组为一个Group
- 逻辑计划上的每个Node都属于某个Scope
- 逻辑计划中的所有Scope组成一棵树
算子/Entity
- 算子是可以被反射的C++类, 用以承载用户逻辑. 具体参见 flume/core/entity.h
- 在所有算子中, 数据流被抽象为无类型的, 每条数据的类型都是void*
- 每个带有输出的Node上必须指定Objector算子, 该算子负责完成数据的序列化和反序列化工作
逻辑执行计划在 flume/proto/logical_plan.proto和entity.proto中定义, 下面给出以上三个概念的proto定义:
message PbLogicalPlan {repeated PbLogicalPlanNode node = 1;repeated PbScope scope = 2;}message PbLogicalPlanNode {enum Type {UNION_NODE = 0;LOAD_NODE = 1;SINK_NODE = 2;PROCESS_NODE = 3;SHUFFLE_NODE = 4;}required string id = 1; // uuidrequired Type type = 2;optional bytes debug_info = 3;optional PbEntity objector = 4;required string scope = 5; // scope uuidoptional bool cache = 6 [default = false]; // indicate if the node need to be cached// according to type, only corresponding member makes senseoptional PbUnionNode union_node = 100;optional PbLoadNode load_node = 101;optional PbSinkNode sink_node = 102;optional PbProcessNode process_node = 103;optional PbShuffleNode shuffle_node = 104;}message PbScope {enum Type {DEFAULT = 0;INPUT = 1; // only accept single LOAD_NODE under this scopeGROUP = 2; // accept BROADCAST/KEY SHUFFLE_NODE under this scopeBUCKET = 3; // accept BROADCAST/SEQUENCE SHUFFLE_NODE under this scope};required string id = 1; // uuidoptional Type type = 2 [default = DEFAULT]; // declare optional for compatible reasonoptional string father = 3; // scope uuidoptional bool is_sorted = 4 [default = false];optional uint32 concurrency = 5 [default = 1]; // a hint for executionoptional PbInputScope input_scope = 101;optional PbGroupScope group_scope = 102;optional PbBucketScope bucket_scope = 103;}message PbEntity { // PbEntity 是可被反射的C++类,可通过类名和config参数来得到相应实例required string name = 1;required bytes config = 2;}
下面分别介绍各个逻辑计划节点.
PROCESS_NODE
PROCESS_NODE是基本的数据处理节点, N入单出, 下面是它的proto定义:
message PbProcessNode {message Input {required string from = 1; // 上游来源节点optional bool is_partial = 101 [default = false]; // 表示是否需要拥有全量数据才能计算(可用于map阶段的预聚合)optional bool is_prepared = 102 [default = false]; // 表示输入是一个Stream还是一个Collection};repeated Input input = 1; // 输入的属性required PbEntity processor = 2; // 实际的处理逻辑,可由用户自定义optional int32 least_prepared_inputs = 101 [default = 0]; // 表示至少有几路输入是Collection才能开始计算}
Processor的接口定义如下:
class Processor {public:virtual ~Processor() {}virtual void Setup(const std::string& config) = 0;// keys传入该record所在Group在Scop中的位置// inputs用来传入可迭代的输入.// emitter用来将结果传给下游节点.virtual void BeginGroup(const std::vector<toft::StringPiece>& keys,const std::vector<Iterator*>& inputs,Emitter* emitter) = 0;// index表示传入的记录属于哪路输入.// 对于第N路输入, 如果inputs[N] != NULL, 则index != Nvirtual void Process(uint32_t index, void* object) = 0;// 当前分组处理结束virtual void EndGroup() = 0;};// Emitter are used to pass result to subsequent execution node.class Emitter {public:virtual ~Emitter() {}// Emit result to subsequent execution node. When Emit returns, object is not needed any more.// If Emit returns false, means no more records is needed by subsequence nodes.virtual bool Emit(void *object) = 0;// No more outputs. User can explicit calling it to cancel execution.virtual void Done() = 0;};class Iterator {public:virtual ~Iterator() {}virtual bool HasNext() const = 0;virtual void* NextValue() = 0;virtual void Reset() = 0;virtual void Done() = 0;};
每个PROCESS_NODE都属于一个Scope, 该Scope存在多组数据. 从每个Processor对象的角度看, 在其生命期内, 其时序关系如下图所示:
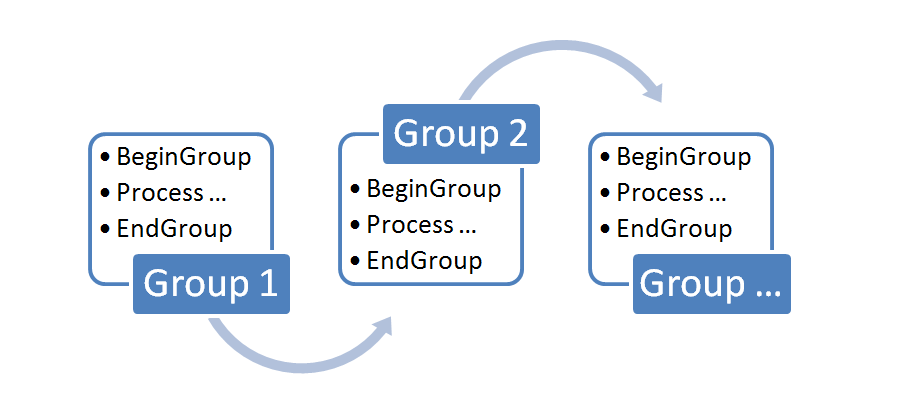
每次Begin-Group周期该Processor处理其所在Scope的一个分组.
LOAD_NODE
LOAD_NODE代表了框架的输入, 每个Load操作会在Global Scope下创建一个新Scope和该Scope下的一个LOAD_NODE. 之所以Load操作会创建Scope, 是因为很多情况下数据是按组存储的, 比如UDW存储中的partition概念.
LOAD_NODE的proto定义如下:
message PbLoadNode {repeated string uri = 1; // 确定数据源所在位置,可以有多个。required PbEntity loader = 2; // 读取数据采取的方式,类似Hadoop的InputFormat}
Loader算子的定义比较接近与Hadoop中InputFormat的设定, 分为且分和读取两个部分. 不同的是, Loader算子并不默认输入都是KeyValue形式的. 另外, 在执行的时候, 每个split都是其数据所在分组的key. Loader算子的接口定义如下:
class Loader {public:virtual ~Loader() {}virtual void Setup(const std::string& config) = 0;// 参数uri指定了数据所在路径,splits是存放了数据切片后的结果,// 如URI、数据起始位置和偏移量. splits中的每个元素, 都会作为Load的参数virtual void Split(const std::string& uri, std::vector<std::string>* splits) = 0;// split是对一个数据块的描述,是 Split() 方法存入的.// 这个方法中是对这个数据块的具体处理逻辑,比如反序列化和简单过滤等。virtual void Load(const std::string& split, Emitter* emitter) = 0;};
SINK_NODE
SINK_NODE代表了框架的输出. 和PROCESS_NODE相同, SINK_NODE也属于某个Scope, 将该组Scope中的每组数据输出到外部系统. SINK_NODE的proto定义如下:
message PbSinkNode {required string from = 1; // 指数据所在位置,可以实现每个scope有不同的输出required PbEntity sinker = 2; // 指输出数据是采取的方式,类似Hadoop的OutputFormat}
Sinker的接口定义如下:
class Sinker {public:virtual ~Sinker() {}virtual void Setup(const std::string& config) = 0;// 打开要写入的文件, 相当于Processor中的BeginGroup.virtual void Open(const std::vector<toft::StringPiece>& keys) = 0;// 写入实际数据。每条记录都是void*类型,由用户自己转换.virtual void Sink(void* object) = 0;// 关闭写入. 具有Commit语义virtual void Close() = 0;};
SHUFFLE_NODE
SHUFFLE_NODE代表分组后的数据流, 由Shuffle操作产生. 其proto定义如下所述:
message PbShuffleNode {// 数据源参与分组的三种方式.enum Type {BROADCAST = 0; // 不参与下面两种处理,所有的记录都会被分发到每一组中KEY = 1; // 表示按key分组,不同的key属于不同的组SEQUENCE = 2; // 表示将数据分桶,预先设定桶数,按照某种策略(如hash)将key分到这些桶中};required string from = 1; // 上游来源节点required Type type = 2;optional PbEntity key_reader = 3; // 表示用来提取key的方式,对应于KEY类型的shuffleoptional PbEntity partitioner = 4; // 表示分桶方式,对应于SEQUENCE类型的shuffle}
Flume支持两种分组方式, 按Key聚集和分桶. 按Key聚集是为参与分组的每条记录附加一个key, 把所有key的记录汇聚到同一组中. 分桶是指事先决定好分组数量, 再把每条记录分配到某个桶中的分组方式.
这个过程中涉及到KeyReader和Partitioner两种算子, 其接口定义如下:
class KeyReader {public:virtual ~KeyReader() {}virtual void Setup(const std::string& config) = 0;// 具体的提取key的逻辑实现,object是整条记录,由用户自己理解其类型.// buffer是最终存放key的变量,要求必须将key转换为char* 存放到buffer中。// wing/common 下的comparable.h中提供了专门方法,生成可用来排序的string类型的key。// 同时提供了升序和降序两种方法。// 返回值是key的实际长度。virtual uint32_t ReadKey(void* object, char* buffer, uint32_t buffer_size) = 0;};class Partitioner {public:virtual ~Partitioner() {}virtual void Setup(const std::string& config) = 0;// 返回该条记录应该属于的分桶.virtual uint32_t Partition(void* object, uint32_t partition_number) = 0;};
UNION_NODE
UNION_NODE用来将多个数据源和合并为一个数据源统一处理, 其proto定义如下:
message PbUnionNode {repeated string from = 1; // 用于合并数据流,repeated字段中存放的是多个上游节点。}
编程实例 - WordCount
这里我们实现一个小程序,用来计算在两个文件中出现频率最高的前50个词.
namespace baidu {namespace flume {namespace runtime {namespace dce {using core::Emitter;using core::Iterator;using core::KeyReader;using core::LogicalPlan;using core::Objector;using core::Processor;// 自定义Loader, 从源文件中读取数据传给下游节点class TextLoader : public core::Loader {public:virtual ~TextLoader() {}virtual void Setup(const std::string& config) {}virtual void Split(const std::string& uri, std::vector<std::string>* splits) {splits->push_back(uri);}virtual void Load(const std::string& split, Emitter* emitter) {std::ifstream fin(split.c_str());std::string line;Record record;while (getline(fin, line)) {record.key = "";record.value = line;emitter->Emit(&record);}}};// 用来切词,并对每个词的出现次数置为1class WordSplitter : public Processor {public:WordSplitter() : m_emitter(NULL) {}virtual ~WordSplitter() {}virtual void Setup(const std::string& config) {}virtual void BeginGroup(const std::vector<toft::StringPiece>& keys,const std::vector<Iterator*>& inputs,Emitter* emitter) {m_emitter = emitter;}virtual void Process(uint32_t index, void* object) {Record* record = static_cast<Record*>(object);std::vector<std::string> words;toft::SplitStringByAnyOf(record->value, " ,.?!:;~@#$%-&*+-()[]{}|<>/\\'\"\n\t\r", &words);for (size_t i = 0; i < words.size(); ++i) {WordSum::ValueType single;single.word = words[i];single.sum = 1;m_emitter->Emit(&single);}}virtual void EndGroup() {}private:Emitter* m_emitter;};// 用来序列化反序列化的方法class WordSum : public Objector {public:struct ValueType {ValueType() : sum(0) {}std::string word;int sum;};virtual ~WordSum() {}virtual void Setup(const std::string& config) {}virtual uint32_t Serialize(void* object, char* buffer, uint32_t buffer_size) {ValueType* value = static_cast<ValueType*>(object);Record record;record.key = value->word;std::string sum_text = boost::lexical_cast<std::string>(value->sum);record.value = sum_text;return m_objector.Serialize(&record, buffer, buffer_size);}virtual void* Deserialize(const char* buffer, uint32_t buffer_size) {Record* record = static_cast<Record*>(m_objector.Deserialize(buffer, buffer_size));ValueType* value = new ValueType();value->word = record->key.as_string();value->sum = boost::lexical_cast<int>(record->value.as_string());m_objector.Release(record);return value;}virtual void Release(void* object) {ValueType* value = static_cast<ValueType*>(object);delete value;}private:RecordObjector m_objector;};// shuffle按key分组,提取分组的key,为单词class WordIdentity : public KeyReader {public:virtual ~WordIdentity() {}virtual void Setup(const std::string& config) {}virtual uint32_t ReadKey(void* object, char* buffer, uint32_t buffer_size) {WordSum::ValueType* single = static_cast<WordSum::ValueType*>(object);if (single->word.size() <= buffer_size) {memcpy(buffer, single->word.data(), single->word.size());}return single->word.size();}};// 统计每个单词个数class WordCount : public Processor {public:WordCount() : m_emitter(NULL) {}virtual ~WordCount() {}virtual void Setup(const std::string& config) {}virtual void BeginGroup(const std::vector<toft::StringPiece>& keys,const std::vector<Iterator*>& inputs,Emitter* emitter) {m_adder.word.clear();m_adder.sum = 0;m_emitter = emitter;}virtual void Process(uint32_t index, void* object) {WordSum::ValueType* value = static_cast<WordSum::ValueType*>(object);CHECK_EQ(1, value->sum);if (m_adder.word.empty()) {m_adder.word = value->word;m_adder.sum = value->sum;} else {CHECK_EQ(m_adder.word, value->word);m_adder.sum += value->sum;}}virtual void EndGroup() {Record record;record.key = m_adder.word;std::string sum_text = boost::lexical_cast<std::string>(m_adder.sum);record.value = sum_text;m_emitter->Emit(&record);}private:WordSum::ValueType m_adder;Emitter* m_emitter;};// 按key分组,提取分组的key,为单词个数class WordNum : public KeyReader {public:virtual ~WordNum() {}virtual void Setup(const std::string& config) {}virtual uint32_t ReadKey(void* object, char* buffer, uint32_t buffer_size) {Record* record = static_cast<Record*>(object);std::string num;int value = boost::lexical_cast<int>(record->value.as_string());::baidu::wing::AppendReverseOrdered(value, &num);if (num.size() <= buffer_size) {memcpy(buffer, num.data(), num.size());}return num.size();}};// CORE部分还没提供 limit 算子,需要自己实现class Limit : public Processor {public:Limit() : m_emitter(NULL) {}virtual ~Limit() {}virtual void Setup(const std::string& config) {m_limit = boost::lexical_cast<int>(config);}virtual void BeginGroup(const std::vector<toft::StringPiece>& keys,const std::vector<Iterator*>& inputs,Emitter* emitter) {m_emitter = emitter;}virtual void Process(uint32_t index, void* object) {if (results.size() < m_limit) {results.push_back(*(static_cast<Record*>(object)));}}virtual void EndGroup() {for (int i = 0; i < results.size(); i++) {m_emitter->Emit(&results[i]);}}private:std::vector<Record> results;Emitter* m_emitter;int m_limit;};// 写入文件使用的 Sinkerclass TextSinker : public core::Sinker {public:virtual ~TextSinker() {}virtual void Setup(const std::string& config) {m_path = config;}virtual void Open(const std::vector<toft::StringPiece>& keys) {m_fout.open(m_path.c_str());}virtual void Sink(void* object) {Record* record = static_cast<Record*>(object);m_fout << record->key << " " << record->value << endl;}virtual void Close() {m_fout.close();}private:std::ofstream m_fout;std::string m_path;};TEST(DceBackendTest, Test) {LOG(WARNING) << "test begin!";toft::scoped_ptr<LogicalPlan> plan(new LogicalPlan());// Map部分LogicalPlan::Node* single_word = plan// 读入两个文件->Load("/home/work/xuekang/tmp/hamlet.txt", "/home/work/xuekang/tmp/hamlet-copy.txt")// 指定Loader和Objector->By<TextLoader>()->As<RecordObjector>()// 指定Processor和Objector->ProcessBy<WordSplitter>()->As<WordSum>();// Shuffle部分,指定分发使用的 KeyReaderplan->Shuffle(plan->global_scope(), single_word)->node(0)->MatchBy<WordIdentity>()// 指定Processor和Objector->ProcessBy<WordCount>()->As<RecordObjector>()// 回到上层scope->LeaveScope()// 对子scope的全量数据做排序,指定 KeyReader->SortBy<WordNum>()// 指定自定义的 Limit Processor和 Objector->ProcessBy<Limit>("50")->As<RecordObjector>()// 指定Sinker和写入的文件->SinkBy<TextSinker>("/home/work/xuekang/tmp/hamlet-output");plan->RunLocally();}} // namespace dce} // namespace runtime} // namespace flume} // namespace baiduint main(int argc, char* argv[]) {::testing::InitGoogleTest(&argc, argv);::google::ParseCommandLineFlags(&argc, &argv, true);::baidu::flume::InitBaiduFlume();return RUN_ALL_TESTS();}
Reference
本节讲述 LogicalPlan 类提供的各个接口.
Load
用于读入数据源,需要指定数据所在的路径。
有两种调用方法:传入包含所有路径的 vector
组成逻辑计划时会在 Global Scope 中创建一个 Scope 和一个 LoadNode ,同时使用 By<Loader>() 方法指定具体使用的 Loader (可自定义), As<Objector>() 方法指定 Objector (可自定义),表示本节点处理完成后传输给下游节点的数据格式。
Sink
用于将结果写入目标路径,调用时要指定写入时使用的Sinker(可自定义)和目的路径。
Process
具体的数据处理逻辑,用户可自己实现此方法。需要指定所属Scope,以及数据来源的节点。
Union
合并多条数据流, 用户只能控制使用的Objector, 合并操作由框架保证。
Shuffle
Shuffle节点, 新建一个scope, 存放为每一个来源节点创建的shuffle node。
shuffle node 可以通过 MatchAny() MatchBy() DistributeAll() 等方法设置不同的shuffle方式,需要指定KeyReader。
ToProtoMessage
将一个节点的相关信息写入pb的message,方便作为执行计划传递给runtime。
RunLocally
本地执行逻辑计划。
Run
远程模式执行逻辑计划,同时指定执行后端和运行资源。


